返回
创建于
状态
公开
深度学习模型全景解析:从CNN到Transformer的技术演进与实践指南
一、卷积神经网络及其进化之路
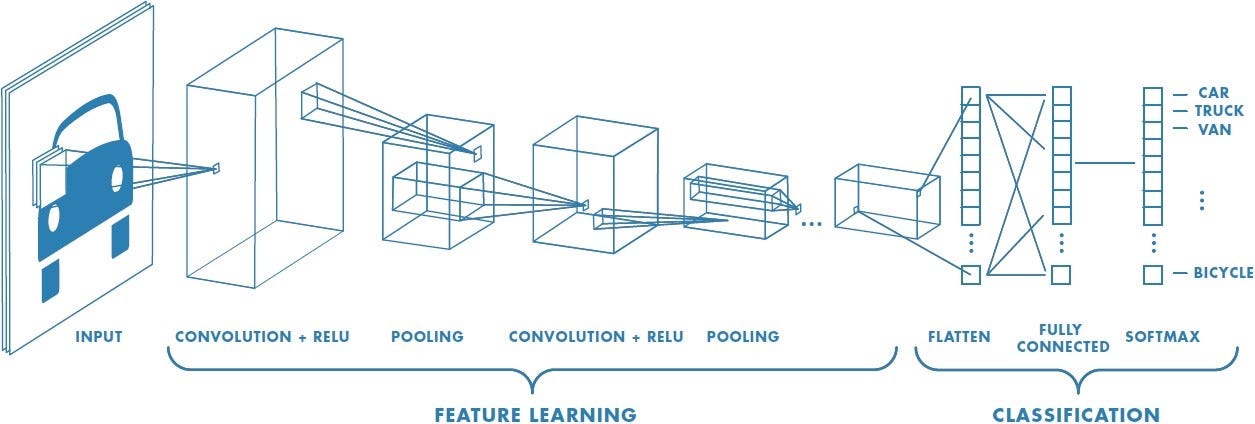
1.1 CNN基础架构与核心原理
卷积神经网络(Convolutional Neural Networks, CNN) 的突破性在于其独特的层次化特征学习能力。核心组件包括:
- 卷积层(Convolutional Layer):通过滑动窗口的滤波器(Filter)提取局部特征,参数共享机制大幅减少参数量
- 池化层(Pooling Layer):最大池化(Max Pooling)和平均池化(Average Pooling)实现特征降维
- 全连接层(Fully Connected Layer):将高级特征映射到分类结果
1# 典型CNN构建示例(PyTorch)
2model = nn.Sequential(
3 nn.Conv2d(3, 16, kernel_size=3, padding=1),
4 nn.ReLU(),
5 nn.MaxPool2d(2),
6 nn.Conv2d(16, 32, kernel_size=3, padding=1),
7 nn.ReLU(),
8 nn.MaxPool2d(2),
9 nn.Flatten(),
10 nn.Linear(32*56*56, 10)
11)1.2 目标检测的进化:从RCNN到YOLO
(1) RCNN系列的技术突破
- Faster R-CNN 的核心创新在于 区域建议网络(Region Proposal Network, RPN):
- 使用3x3滑动窗口在特征图上生成9种尺度的锚框(Anchor)
- 通过两个1x1卷积层分别预测目标概率(Objectness Score)和边界框偏移量
- 与检测网络共享特征图,实现端到端训练
1# RPN实现伪代码
2class RPN(nn.Module):
3 def __init__(self, in_channels):
4 self.conv = nn.Conv2d(in_channels, 512, 3, padding=1)
5 self.cls_layer = nn.Conv2d(512, 9*2, 1) # 9 anchors, 2 scores
6 self.reg_layer = nn.Conv2d(512, 9*4, 1) # 4 coordinates(2) YOLO的实时检测革命
YOLOv5 的主要改进:
- 自适应锚框计算:通过k-means聚类训练集目标尺寸
- Mosaic数据增强:四图拼接提升小目标检测能力
- CSPDarknet53 主干网络:跨阶段局部连接减少计算量
- PANet特征金字塔:加强多尺度特征融合
(3) SSD的多尺度检测策略
SSD(Single Shot MultiBox Detector) 的关键设计:
- 在多个特征层级(如Conv4_3, Conv7等)进行检测
- 每个特征点关联不同长宽比的默认框(Default Box)
- 使用难例挖掘(Hard Negative Mining)平衡正负样本
1.3 实例分割的巅峰:Mask R-CNN
- RoIAlign:改进RoIPooling的量化误差,实现亚像素级特征对齐
- 并行分支设计:在Faster R-CNN基础上增加掩码预测分支
- 典型应用:COCO数据集实例分割(mAP 37.1%)
二、Transformer的跨界颠覆
2.1 Vision Transformer工作机制
ViT 的预处理流程:
- 图像分块(Patch):224x224图像 → 16x16的196个patch
- 线性投影:将每个patch展平为768维向量(ViT-Base)
- 添加位置编码:可学习的位置嵌入(Learnable Positional Embedding)
1# ViT的Patch Embedding实现
2class PatchEmbed(nn.Module):
3 def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
4 super().__init__()
5 self.proj = nn.Conv2d(in_chans, embed_dim,
6 kernel_size=patch_size,
7 stride=patch_size)
8
9 def forward(self, x):
10 x = self.proj(x).flatten(2).transpose(1, 2)
11 return x2.2 Swin Transformer的层级设计
- 滑动窗口注意力:限制自注意力计算在局部窗口内
- 窗口移位(Shifted Window):实现跨窗口信息交互
- 四个阶段的下采样:逐步扩大感受野

三、模型选型与工程实践
3.1 目标检测模型对比
| 指标 | Faster R-CNN | YOLOv5s | SSD300 |
|---|---|---|---|
| mAP (COCO) | 37.9% | 36.7% | 29.5% |
| FPS (T4 GPU) | 12 | 123 | 46 |
| 参数量 | 41M | 7.2M | 24M |
3.2 部署优化技巧
- 模型量化:FP32 → INT8量化(TensorRT)
- 剪枝策略:基于重要性的通道剪枝
- 知识蒸馏:大模型向小模型的知识迁移
- ONNX转换:实现跨框架部署
1# TensorRT量化示例
2builder = trt.Builder(TRT_LOGGER)
3network = builder.create_network()
4parser = trt.OnnxParser(network, TRT_LOGGER)
5config = builder.create_builder_config()
6config.set_flag(trt.BuilderFlag.INT8)
7config.int8_calibrator = calibrator
8engine = builder.build_engine(network, config)四、前沿趋势与挑战
4.1 多模态融合
- CLIP(Contrastive Language-Image Pretraining):图文对比学习
- DALL·E 2:文本引导的图像生成
4.2 高效架构设计
- MobileOne:移动端优化的CNN架构(<1ms延迟)
- EdgeNeXt:面向边缘设备的轻量级Transformer
4.3 自监督学习
- MAE(Masked Autoencoder):图像掩码重建预训练
- MoCo v3:对比学习的稳定训练方法
五、常见问题与解决方案
5.1 小目标检测优化
- 数据层面:Mosaic增强、过采样小目标
- 模型层面:改进特征金字塔(如BiFPN)
- 后处理:自适应NMS阈值
5.2 模型过拟合应对
- 正则化:Stochastic Depth、DropPath
- 数据增强:MixUp、CutMix
- 早停策略:监控验证集损失
5.3 部署中的精度损失
- 量化感知训练(QAT)
- 校准集精细调整
- 混合精度部署
展望:当前模型架构呈现CNN与Transformer融合的趋势,如ConvNeXt通过改进传统CNN达到Swin Transformer的性能。未来,自适应计算(Adaptive Computation)和神经架构搜索(NAS)将继续推动模型效率的提升,而多模态预训练大模型将重塑产业应用格局。工程师需要持续跟踪基础理论进展,同时注重实际部署中的工程优化,才能在AI落地浪潮中保持竞争力。